Waymark - developing eval infrastructure for AI creative quality
At Waymark I was responsible not just for making the AI video quality better, but for knowing whether I actually had. Supporting that required a suite of internal testing tools I built using AI-assisted development, primarily Bolt and Replit, at a pace that would have been impossible through normal engineering cycles.
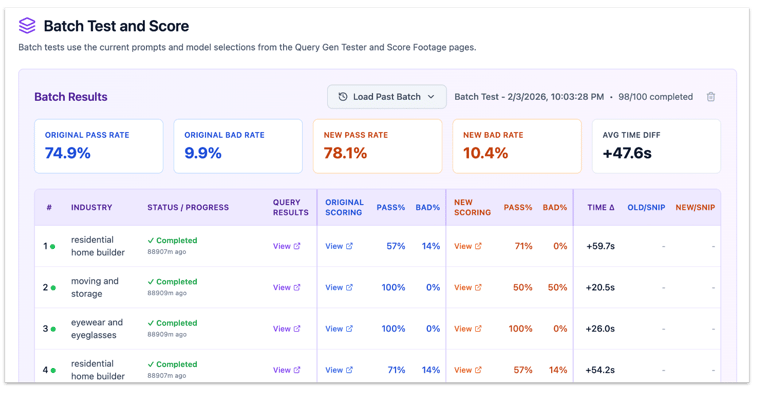
The toolset grew alongside the pipeline work: a footage search and scoring explorer, a query generation lab comparing production against in-development versions, batch processing across datasets of 100 or more real businesses, and purpose-built testers for color, image selection, and scriptwriting. Every tool shared the same architecture: the same auth pattern, the same model selector, the same prompt version management interface.
AI-ASSISTED DEVELOPMENT
LLM EVALUATION
PRODUCT MANAGEMENT
TEAM LEADERSHIP


That consistency came from turning the development process itself into a system to optimize. After analyzing a transcript of one of my own early Bolt sessions, I found roughly 40-50% of iteration time was going to recurring failure patterns. I redesigned around a spec-first workflow with reusable boilerplate and structural patterns adapted per tool. Each subsequent tool launched faster than the last -- using AI to improve AI development is a compounding skill, and one that transfers regardless of which tools you're using.
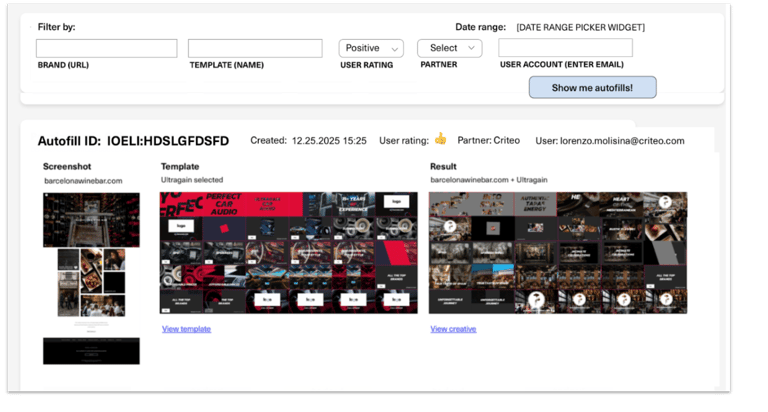
I conceived and spec'd two tools for engineering that shortcut the QA process. The Batch Generator creates scores of autofills from a URL list in minutes, making controlled before-and-after comparison possible at scale. The Autofill Snapshot tool let the team review videos frame by frame as a contact sheet, without having to watch each one.
No tool can fully replace human judgment on creative quality. I also defined a nine-dimension rubric covering footage selection, color selection, image selection, text, script, logo, template selection, (lack of) cut-off faces, and overall brand fit, each scored on a four-point scale from TV-ready to reject and redo. The Autofill Voting Station distributed this across the team, managing weekly review runs and aggregating scores by category. In the final weeks, seven reviewers were scoring twenty or more videos per run, using test runs that took me 10 minutes to set up.
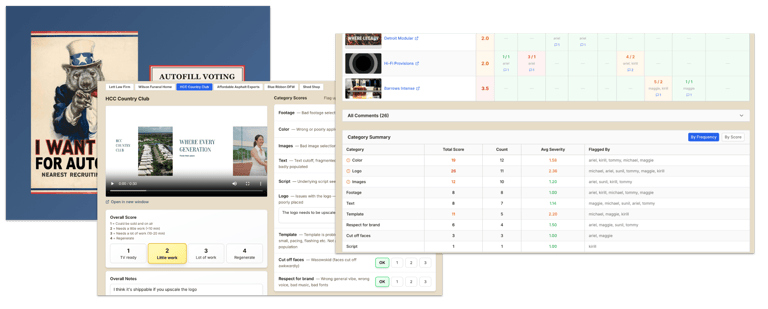
The data was actionable in both directions: when color and logo issues topped the rankings, that directed the next round of work. When footage flags dropped after the pipeline shipped, that confirmed the improvement was real.
What tied all of it together was treating the improvement process itself as an engineering problem -- building the tooling, the data infrastructure, and the evaluation framework needed to move fast and measure without bias.