Waymark - improving AI-generated TV/video creative quality
Waymark is a self-service platform that uses AI to generate video ads for small businesses. When I joined to lead product, picking up work previously done by the CEO, the central challenge was decomposing quality into something measurable and improvable. I structured work around three tracks, grew a PM into a Sr. PM who took independent ownership of one, and went deep on Quality myself.
PROMPT ENGINEERING
LLM EVALUATION
PRODUCT STRATEGY
TEAM LEADERSHIP
AI-ASSISTED DEVELOPMENT
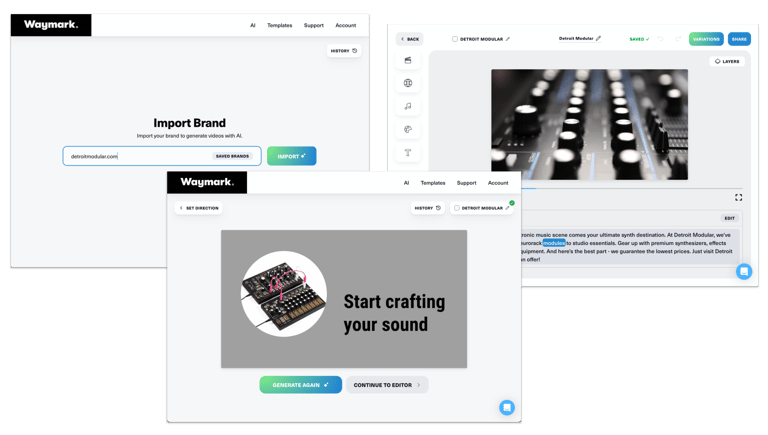
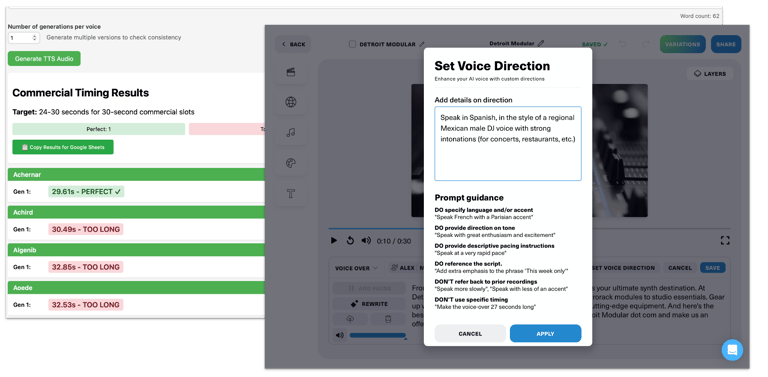
When I joined, "robotic voices" was the #1 customer complaint. The path to solving it wasn't obvious. We didn't know whether a new provider could deliver the expressiveness we needed, and getting there required extensive testing and prompt iteration. Consistent audio length was its own challenge: TV and video ads have fixed time slots, and the new voices had to hit them reliably.
I built a batch testing tool that generated voice-overs across the full set of available voices from a single script, measured each output against the target window, and iterated on the prompt until standard deviation across scripts was low enough to be reliable.
The new voices were fully promptable and natively multilingual, and the result was Waymark's first directly user-promptable feature, letting users specify accent, tone, and pacing in natural language. Those capabilities were a factor in winning the largest Spanish-language broadcaster in the US as a client.
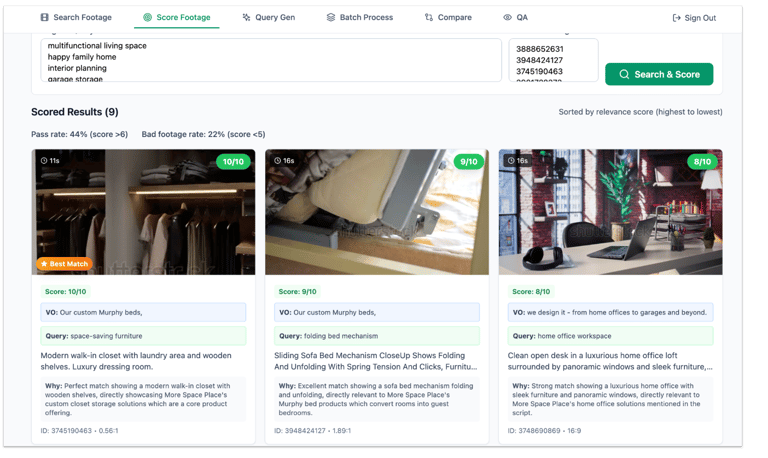
Footage selection was another top quality issue. The existing pipeline filtered on a narrow keyword list, generated a single query per slot matched primarily to the voiceover snippet, and had no visual analysis. Clips could pass every text filter and still be animation or a green screen.
The redesigned pipeline expanded pre-filtering substantially, restructured query generation around three signals weighted toward brand relevance rather than literal voiceover match, and added a vision model stage to evaluate clip thumbnails. Scoring moved from a single dimension to separate brand, script, and voiceover fit components. The result was a 100% reduction in disqualifying footage and at least 50-60% fewer off-brand selections.
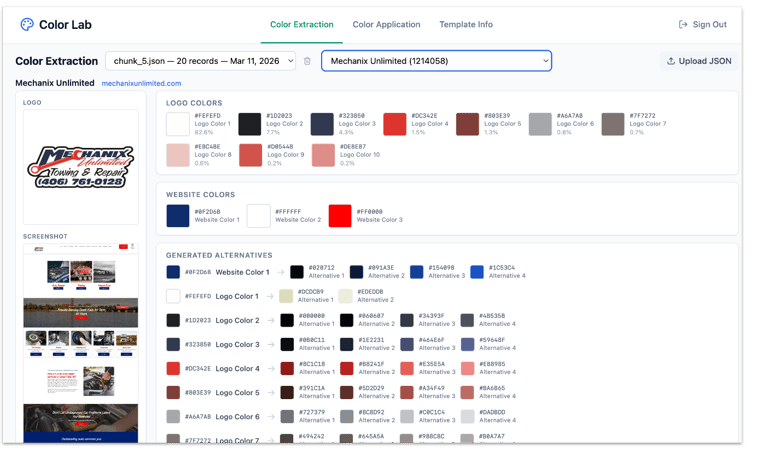
Color application required solving a structural problem first. Without a model of how a template is visually organized, an LLM applying brand colors will get the values right and the result wrong. I developed a two-step approach: first generating a structured map of each template's color logic, then applying brand colors with that map as context. Separating the two problems made each more tractable.
Brand color extraction from website screenshots was a distinct thread, using vision model prompting to pull accurate color and layout information from rendered pages. I also worked on image selection, diagnosing an existing pipeline's weak points and proposing structural improvements, and on scriptwriting prompts oriented toward narrative structure rather than feature enumeration.
Across all of this I led the prompt engineering, collaborating with the lead engineer on feedback and review. I used GitHub Copilot to document pre-existing pipelines in enough detail to know what needed to change. I introduced versioned prompts with changelogs, ran iterative testing against real production data, and benchmarked across Claude, Gemini and GPT capability tiers to build a working understanding of comparative speed, cost, and task-specific performance.
Building the testing infrastructure to support all of this was its own body of work, covered in more detail on the next page.